PyramidCodec: Hierarchical Codec for Long-form Music Generation in Audio Domain
Abstract
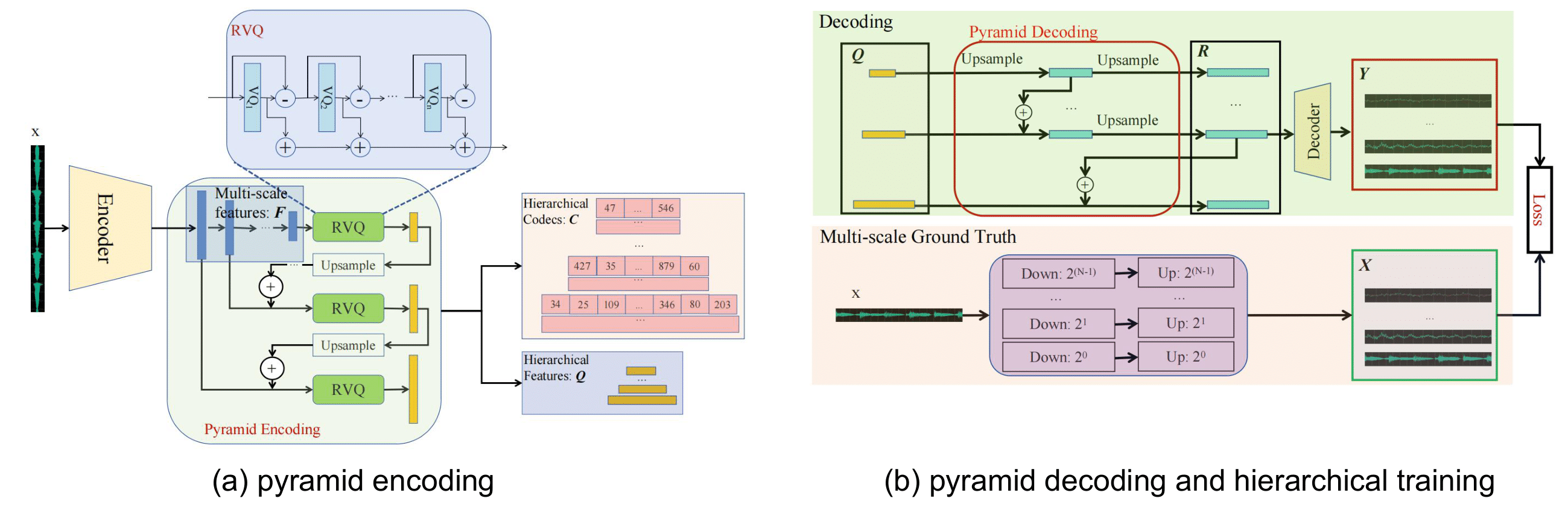
Generating well-structured long music compositions, spanning several minutes, remains a challenge due to inefficient representation and the lack of structured representation. In this paper, we propose PyramidCodec, a hierarchical discrete representation of audio, for long audio-domain music generation. Specifically, we employ residual vector quantization on different levels of features to obtain the hierarchical discrete representation. The highest level of features has the largest hop size, resulting in the most compact token sequence. The quantized higher-level representation is up-sampled and combined with lower-level features to apply residual vector quantization and obtain lower-level discrete representations. Furthermore, we design a hierarchical training strategy to ensure that the details are gradually added with more levels of tokens. By performing hierarchical tokenization, the overall token sequence represents information at various scales, facilitating long-context modeling in music and enabling the generation of well-structured compositions. The experimental results demonstrate that our proposed PyramidCodec achieves competitive performance in terms of reconstruction quality and token per second (TPS). By enabling ultra-long music modeling at the lowest level, the proposed approach facilitates training a language model that can generate well-structured long-form music for up to 3 minutes, whose quality is further demonstrated by subjective and objective evaluations.
Music Continuation Samples
The following samples are music continuation samples. The first 10 senconds of music are prompts and the remaining 30 seconds are composed with different methods.
Explanation: The AudioLM baseline notably underperforms in both audio quality and musicality, primarily due to the inefficient Encodec and the lack of re-training on the audio-converted LAKH dataset. Generally, "DAC-TPS86" suffers from excessive repetition, poor musical progression and poor instrumental consistency. We highlight how our method, "Pyramid-TPS70," performs better compared to "DAC-TPS86." For example, assigning numbers to the examples using row-major order, sample 1 of "DAC-TPS86" exhibits a monotonous and repetitive rhythm. A disharmonious instrument can be heard at 16-17 seconds in sample 3, while in sample 4, disharmony occurs around 35 seconds. In sample 6, an instrument drops out after approximately 15 seconds. The differences in sample 2 and sample 5 may be subjective and based on individual taste.
Ground Truth
DAC-TPS86
AudioLM-TPS600
Pyramid-TPS70
Long-form Music Generation from Scratch
The following samples are generated using PyramidCodec for tokenizer and tiny-GPT2 (40M trainable parameters) as language model. We recommend that listeners focus on aspects such as coherence, rhythm, and adherence to musical conventions.
Sample1-3
Sample4-6
Sample7-9
Sample10-12
Sample13-15